AI 视频生成正将生产模式从“拍摄-剪辑”转向“描述-生成”。其核心是通过深度学习模型(如扩散模型与 Transformer)将文本、图像或音频转化为动态画面。到 2026 年 3 月,该技术已从早期的短时扭曲画面,进化为能够维持视觉一致性、模拟物理规律且具备商业可用性的长视频片段。
目前市场分化为两个极端:一端是追求电影级物理真实的视觉创作,另一端是追求高转化率与低成本的电商短视频自动化。这意味着 AI 视频并非一个“一键生成”的按钮,而是一套需要精准调优的生产管线。
核心原理:时空补丁与潜空间去噪
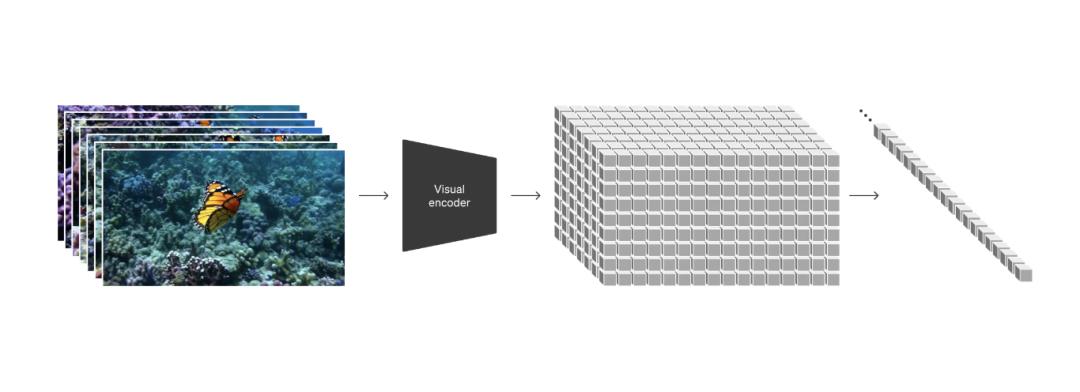
顶尖模型通过“时空补丁”机制解决了视频生成的连续性问题。 模型不再是逐帧生成图片,而是将视频切分为空间(长宽)与时间(帧顺序)的小方块同步计算。由于模型能感知物体在三维空间中的运动轨迹,而非单纯猜测下一帧内容,因此解决了此前常见的“物体消失”或“肢体打结”问题。
潜在扩散模型(Latent Diffusion Model)则在效率上实现了突破。 计算在压缩后的“潜空间”而非原始像素层进行。当输入“猫在雨中奔跑”时,模型先在潜空间构建语义关联,最后解码为 4K 画面。这种机制大幅降低了算力开销,使得实时预览成为可能。
商业化工作流实操指南
专业生产不能依赖简单的对话框 Prompt,而应遵循:脚本拆解 $\rightarrow$ 视觉基准 $\rightarrow$ 分镜生成 $\rightarrow$ 动态增强 $\rightarrow$ 后期合成。
第一步:确立视觉基准(Visual Baseline)

必须先生成静态基准图,严禁直接生成视频,否则画面会随时间产生严重漂移。
2. 将图片作为 Image Prompt 输入视频模型,将 Image Weight 调至 0.8 以上,强制模型遵循视觉设定。
3. 若出现衣服颜色变化,使用局部重绘(Inpainting)锁定不变区域,仅允许肢体产生动作。
第二步:精准动态控制
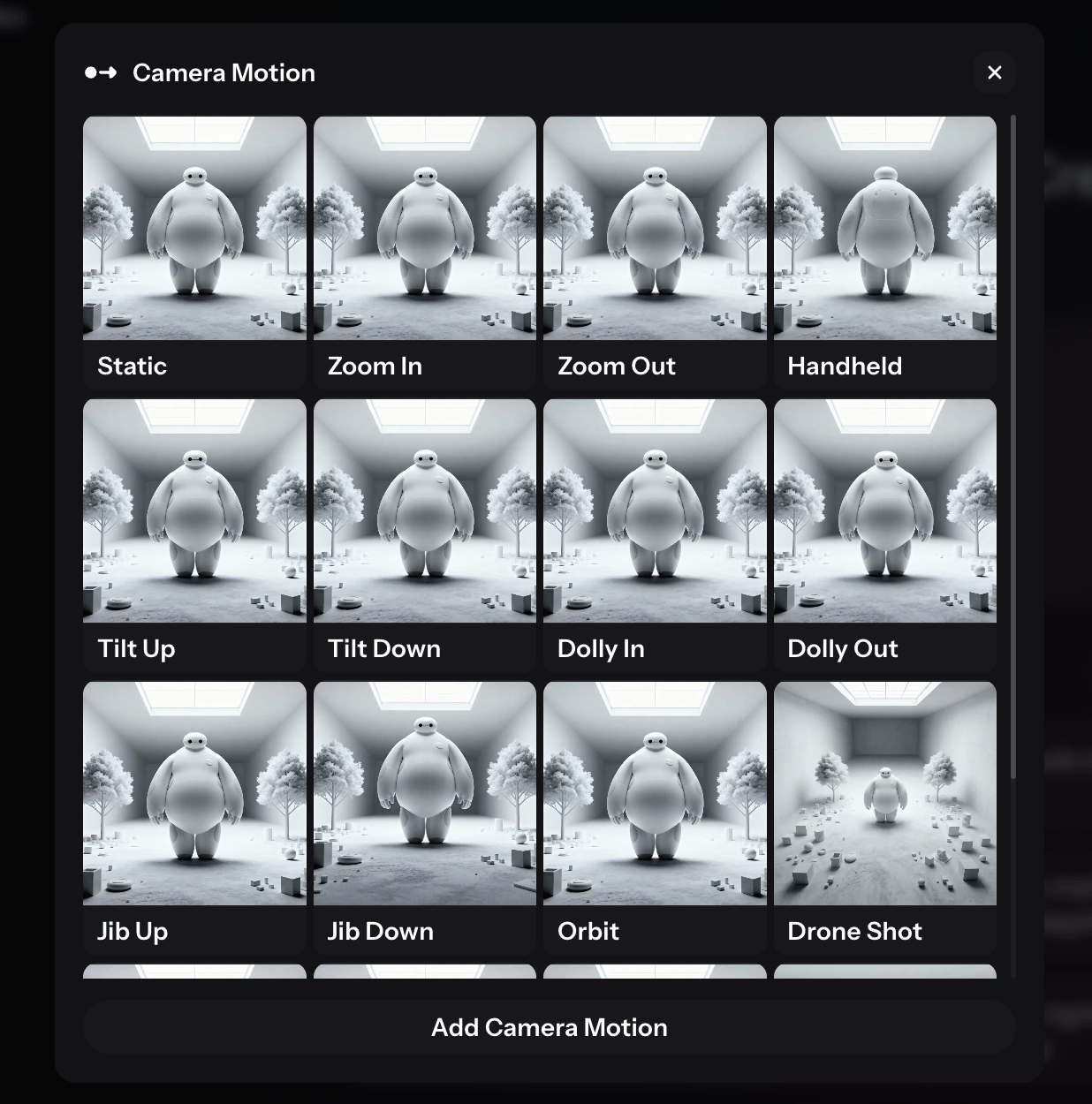
放弃文学化描述,采用“主体 + 动作 + 镜头语言 + 环境光影”的结构化指令。
Slow zoom-in, 35mm lens, shallow depth of field2. 调整运动强度参数(Motion Bucket): 产品展示建议设在 3-5 之间以保持稳定;动作大片设在 7-9 之间。画面崩坏时,优先降低该数值。
3. 修正不自然动作: 若人物行走像在滑冰,可在 Prompt 中加入 “weight shift”(重心转移)或 “footsteps touching the ground”(脚步触地)。
第三步:电商产品快速转化

针对电商平台,优先选择支持 URL 或图片直接生成的垂直工具。
2. 选用“痛点解决”或“生活方式”模板,单段脚本时长控制在 3 秒内,避免观众流失。
3. 检查产品与背景的阴影融合度,调整“环境光融合度”参数确保真实感。
4. 导出 9:16 竖屏 H.265 编码 MP4,确保移动端加载速度与画质平衡。
方案对比:电影级 vs 电商级
| 维度 | 电影级(Sora/Veo/Runway Gen-3) | 电商级(Tagshop AI/HeyGen) | ||
|---|---|---|---|---|
| 核心目标 | 视觉冲击力、叙事感 | 快速出片、高转化率、产品真实性 | ||
| 成本 | 高(按计算时长或高额订阅计费) | 中(按项目数或月度套餐计费) | ||
| 控制精度 | 较低(依赖 Prompt 抽卡,后期难改) | 较高(可精确控制产品位置与文本) | ||
| 风险点 | 版权争议较大,物理规律偶有错误 | 适用场景 | 品牌宣传片、电影预告、概念短片 | 亚马逊列表、TikTok 投放、产品演示 |
局限性与风险提醒
AI 视频在特定场景中仍存在技术死角,建议在以下情况坚持使用传统拍摄或 3D 建模:
1. 精密工业演示如何处理?
AI 易在微小机械连接处产生“融合”现象,导致技术参数传递错误。此时 Blender 或 C4D 是唯一可靠选择。
2. 情感细腻的特写能用 AI 吗?
AI 能模拟哭泣的肌肉运动,但无法表现“欲言又止”等克制的情绪深度,难以触达深层的情感共鸣。
3. 法律版权风险如何规避?
许多模型训练集涉及未授权作品。若项目面临严苛的法律背书,完全依赖 AI 生成可能在未来陷入版权诉讼,因为目前的版权法尚未完全覆盖生成式 AI。
行动建议
不要试图用 AI 替代整个团队,而要用它替代“寻找素材”和“初步打样”阶段。 建议建立个人“视觉素材库”,存档成功的 Prompt 和基准图。先从低风险的内部 Demo 或电商短视频入手,跑通“图像 $\rightarrow$ 视频 $\rightarrow$ 剪辑”的闭环,而非直接尝试制作长篇 AI 电影。